![[forCode]](http://www.forcode.es/wp-content/uploads/2014/10/forCode_default.png)
En este post entramos ya en detalle con las clases en C++. Veremos como declararlas, definir campos, métodos y varias cosillas más referentes al ciclo de vida de los objetos en C++.
Para crear una clase en C++ debemos colocar su declaración en el fichero de cabecera y luego su definición (es decir, el código de sus métodos) en el fichero .cpp asociado.
Vamos a ir paso a paso. Empezaremos por una clase, Beer.h que tendrá una cadena para guardar su nombre. En este caso en el fichero Beer.h tendríamos el siguiente código:
#pragma once
#include <string>
class Beer
{
std::string _name;
};
El tipo std::string es la clase usada en C++ para representar cadenas. Dicha clase está definida en el fichero «string» (así, sin extensión .h) de ahí que incluyamos dicho fichero. Los ficheros de cabecera estánderes de C++ no usan la extensión .h, para diferenciarlos de los ficheros de cabecera estándares de C. La recomendación es que tus ficheros de cabecera si que usen la extensión .h, o alguna otra variante como .hxx.
Quizá te sorprenda que en la directiva #include se coloque el nombre de fichero entre los símbolos < y > en lugar de usar comillas. Cuando se usan los símbolos < y > le indicamos al preprocesador que busque este fichero en los directorios en los que están los ficheros de cabecera estándares, que vienen con el compilador. Por su parte cuando usamos comillas, le indicamos al preprocesador que busque el fichero en la misma ruta que el fichero .cpp
Ahora podríamos crear un objeto de tipo Beer y establecer su nombre:
Beer beer; beer._name = "Punk IPA";
Este código no compila. Y la razón es que _name es una variable privada de la clase Beer. Recuerda que si Beer fuese una struct, el código si que compilaría. Para hacer que _name sea publica, basta con colocar la variable dentro de la sección public: de la clase:
class Beer
{
public:
std::string _name;
};
Todo lo que siga a la sección «public» será público, hasta que termine la declaración de la clase o se encuentra otra sección. Es decir, no especificamos si cada miembro (variable o método) es público, privado o protegido, si no que lo colocamos dentro de la sección (public, private, protected) correspondiente. La sección por defecto es private en las clases y public en las structs (siendo esa su única diferencia). Que aprezcan dos o más secciones del mismo tipo (p. ej. dos públicas o dos privadas) es correcto y no genera error alguno.
Vamos a colocar la variable _name como privada y en su lugar crearemos un par de métodos getName y setName para obtener y establecer su valor. A diferencia de C#, C++ no tiene la noción de propiedades. Para ello en el fichero Beer.h colocamos lo siguiente:
class Beer
{
std::string _name;
public:
std::string getName();
void setName(std::string);
};
Ahora si creas un objeto Beer puedes llamar a su método setName:
Beer beer;
beer.setName("Punk IPA");
Este código compila correctamente. Igual esto te sorprende porque en ningún momento hemos definido las funciones getName y setName. ¿Como puede compilar el código? Pues, porque, a diferencia de otros lenguajes como Java y C# que llamamos «compilar» al proceso de construir el ejecutable (sea en código intermedio o final) a partir del código fuente, en C++ cuando decimos «compilar» nos referimos al proceso de generar código objeto a partir de código fuente. Es decir, a la tarea del compilador. Pero en C++ una vez el código ha compilado, entra el enlazador (linker en inglés) para realizar el enlazado, que es el paso final. En enlazado consiste, básicamente, en «enlazar» el código objeto que llama a funciones con la definición de dichas funciones, que pueden estar en el mismo codigo objeto o en un código objeto externo (una librería).
Por lo tanto, el código da un error, pero no de compilación, sino de enlazado. En concreto VS2015 se queja con el siguiente mensaje:
LNK2019 unresolved external symbol «public: void __thiscall Beer::setName(class std::basic_string<char,struct std::char_traits<char>,class std::allocator<char> >)» (?setName@Beer@@QAEXV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@std@@@Z) referenced in function _wmain
El mensaje es un poco críptico (bienvenido a C++) pero podemos ver que es un mensaje del enlazador (su código es LNK y un número) y que el enlazador se queja de un «unresolved external symbol». Esto es: un símbolo (en este caso setName) que el compilador ha indicado que se utiliza pero que el enlazador no encuentra ni dentro del código objeto compilado ni en cualquier otra librería enlazada. El hecho de que el mensaje sea tan largo es porque el enlazador y el compilador hablan entre ellos en un idioma un poco raro… vamos que los nombres de funciones que ve el enlazador no son los que nosotros tenemos en el código fuente si no que están decorados por el compilador. Lo que vemos aquí és el decorated method name del método setName.
Pero en resumen, siempre que tengas unresolved externals significa que el enlazador no es capaz de encontrar la definición (es decir, el código) de una función (o método) que estás usando. Si este método pertenece a tu código, significa básicamente que no lo has incluído (como es el caso), si el método pertenece a una librería externa significa que no estás enlazando dicha librería.
Vamos ahora a definir los métodos de la clase Beer. Para ello, en el fichero Beer.cpp debemos colocar el siguiente código:
#include "Beer.h"
std::string Beer::getName() {
return _name;
}
void Beer::setName(std::string newName) {
_name = newName;
}
Fíjate que las funciones que pertenecen a una clase se definen precedidas del nombre de la clase utilizando el operador de ámbito (::). Así en lugar de la función getName() definimos la función Beer::getName(). Con esto el compilador sabe que esta es la función getName de la clase Beer. De esta manera el fichero Beer.cpp podría contener todas o parte de las funciones de la clase Beer, además de funciones globales o funciones de otras clases. No hay en C++ una correspondencia clara entre ficheros de código fuente y clases (aunque es buena práctica tener cada clase en su fichero cpp).
Dentro del código de Beer::getName o Beer::setName podemos acceder a la variable _name, aunque era privada. Si queremos podemos usar this para referirnos al propio objeto. Ojo, que this es un puntero (en este caso un puntero a Beer, es decir un Beer*), así que debemos usar this->_name y no this._name. El uso de this es opcional.
Constructores y destructores
Toda clase tiene dos métodos especiales llamados constructor y destructor. El constructor se llama cuando se crea un objeto y sirve para establecer su estado inicial y reservar recursos que el objeto pueda requerir. El destructor se llama cuando se destruye un objeto y su responsabilidad es liberar los recursos que el objeto esté usando.
Si nosotros no definimos explícitamente el constructor o el destructor, el compilador crea uno público por defecto.
El constructor es una función cuyo nombre es el mismo que el nombre de la clase y que no tiene ningún tipo de retorno (ni void, ni nada). Por su parte el destructor es una función cuyo nombre es el nombre de la clase pero precedido por el símbolo ~. Al igual que el constructor no tiene tipo de retorno. Al margen de eso son funciones «normales» por lo que debemos declaralas en la clase (en el fichero de cabecera) y definirlas en el fichero .cpp. En el fichero de cabecera podríamos tener:
class Beer
{
std::string _name;
public:
std::string getName();
void setName(std::string);
Beer();
~Beer();
};
Podemos ver al constructor y al destructor declaradas como las dos últimas funciones de la sección pública de la clase.
El destructor suele declararse siempre como público. Si una clase no tiene el destructor público no pueden crearse objetos de dicha clase en la pila, sólo en el heap. Además los objetos creados en el heap no pueden ser eliminados directamente (con «delete»). Deben ser eliminados indirectamente (a través de una función pública que invoque al destructor privado). Eso permite construir en C++ sistemas de objetos basados en contadores de referencias, entre otras cosas. Por su parte el constructor suele ser público, pero puede ser protegido o privado. Un constructor privado sirve para que solo se puedan crear objetos a través de otra función (que actúe como factoría), mientras que un constructor protegido evita que alguien pueda crear objetos de una clase base (solo se podrán crear objetos de las clases derivadas, si estas tienen el constructor público).
En el fichero .cpp definiríamos ambas funciones:
Beer::Beer()
{
std::cout << "Beer ctor.\n";
}
Beer::~Beer()
{
std::cout << "Beer [" << _name << "] destructor.\n";
}
En nuestro caso, constructor y destructor no hacen nada salvo imprimir un mensaje por pantalla. En una clase más compleja el constructor crearía los recursos y el destructor los destruiría. Supongamos ahora el siguiente código:
for (auto idx = 0; idx < 10; idx++) {
auto beer = Beer();
beer.setName("Beer " + std::to_string(idx));
}
Dicho código imprimirá lo siguiente por pantalla:
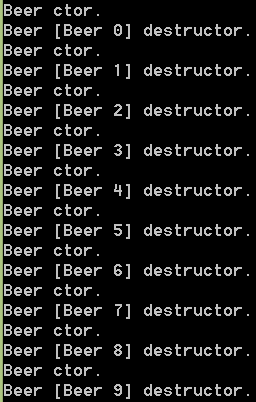
Observa que se llama al constructor, y luego al destructor una vez el objeto sale de ámbito. El objeto se crea en la pila, dentro del bucle, por lo que al salir de él, el destructor es ejecutado sí o sí.
Las cosas cambian si los objetos los creamos en el heap (usando new), en este caso la invocación del destructor no es automática, ya que lo que new devuelve no es un objeto, si no un puntero a un objeto, y dado que dos o más punteros pueden apuntar al mismo objeto, no es posible destruír el objeto cuando un puntero sale de ámbito (ya que podrían quedar otros punteros apuntando al mismo objeto). Es por eso que en este caso debemos llamar a delete para borrar el objeto cuando ya no vayamos a usarlo. Si no llamas a delete tienes un memory leak, y si llamas a delete antes de tiempo tienes un dangling pointer. Tanto memory leaks como dangling pointers son problemas difíciles de detectar y de depurar. Eso, que es lo que conocemos por la gestión manual de la memoria en C++, es una de las razones por las que mucha gente no quiere usar C++ y se pasa a lenguajes como Java y C# que tienen garbage collector. La lástima es que mucha gente, hoy en día, sigue ignorando C++ por la gestión manual de la memoria, cuando la realidad es, que si hoy en día usas new y delete para gestionar la memoria en C++ lo estás haciendo mal. Hay maneras mejores en C++ para gestionar la memoria, sin perder rendimiento y manteniendo la predictibilidad en la destrucción de objetos… Ya llegaremos a ellas a su debido momento.
Bueno… lo dejamos aquí por el momento. En el siguiente post seguiremos viendo más temas sobre las clases en C++.